
What happens when six leading AI models are asked to analyze the same legal scenario?
Which one reasons like a junior solicitor — and which one collapses under doctrinal pressure?
To answer these questions, we ran a controlled benchmark using the BULORΛ.ai – Legal Reasoning Module, applied to a realistic UK legal case study on constructive dismissal.
Below is a breakdown of the methodology, the scenario, and the results — including a model-by-model analysis.
The results presented constitute an exploratory analysis based on interactions observed at a given point in time.
They do not constitute a certification, nor a definitive legal qualification of the model or its provider.
Model performance and behavior may vary depending on the version, context, prompt, and configuration.
📌 The Scenario: A Realistic UK Constructive Dismissal Case Study
We used the following structured test prompt (Legal Case Study mode):
Emma, a senior analyst at Northbridge Capital, resigns after 6 years…
She alleges impossible deadlines, HR inaction, exclusion from key meetings, and anxiety symptoms.
Northbridge denies all wrongdoing, citing staff shortages and workflow restructuring.
The legal question:
Does Emma have a viable claim for constructive dismissal under UK employment law, including the “last straw” doctrine?
This scenario is ideal because it requires:
- fact qualification
- identification of legal issues
- application of UK precedents (Sharp, Malik, Kaur, Omilaju…)
- use of statutory sources (ERA 1996, Equality Act 2010)
- structured reasoning
- critical discussion
In other words: perfect stress test for an LLM’s legal reasoning capabilities.
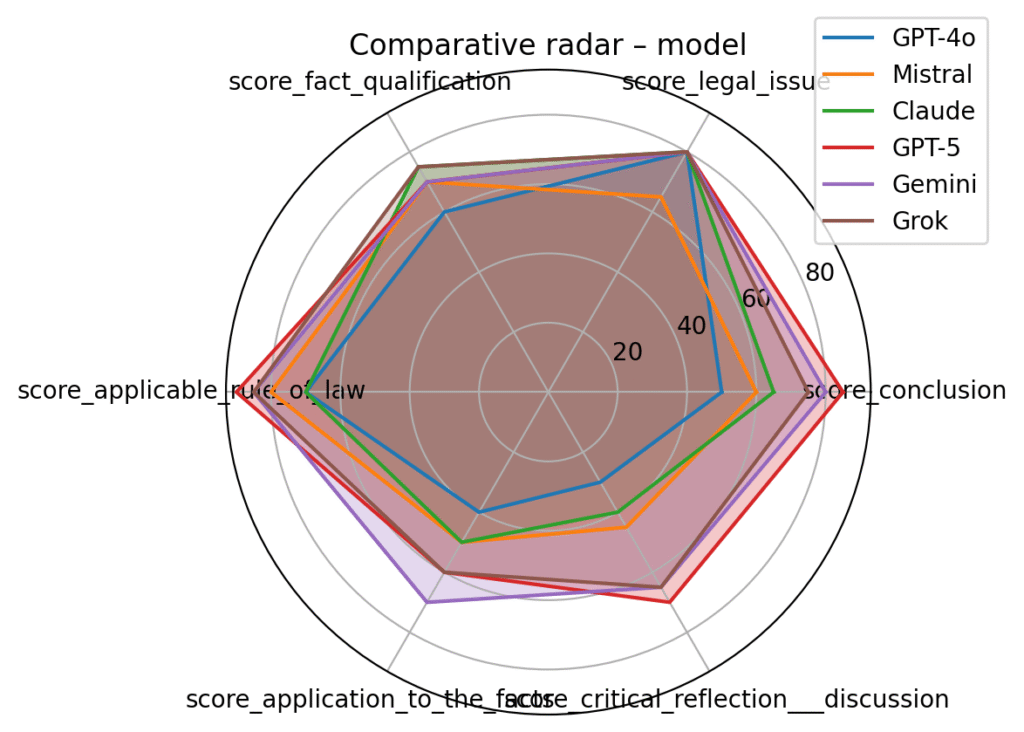
📊 Results Overview (Scores /100)
Models tested:
| Model | Overall Score | Strengths | Weaknesses |
|---|---|---|---|
| GPT-5 | 75/100 | Deep case law, precise rule application | Needs tighter fact structuring |
| Gemini | 75/100 | Balanced reasoning, good doctrinal recall | Limited critical reflection |
| Grok | 72/100 | Solid structure, good comparisons | Weak application depth |
| Claude | 62/100 | Clear narrative | Shallow legal grounding |
| Mistral | 60/100 | Correct principles | Weak application + reasoning |
| GPT-4o | 54/100 | Acceptable global structure | Misses legal depth entirely |
Key insight:
➡️ The gap between the models is real and measurable.
GPT-5 and Gemini perform close to junior lawyers.
Claude, Mistral, GPT-4o behave more like “general-purpose assistants.”
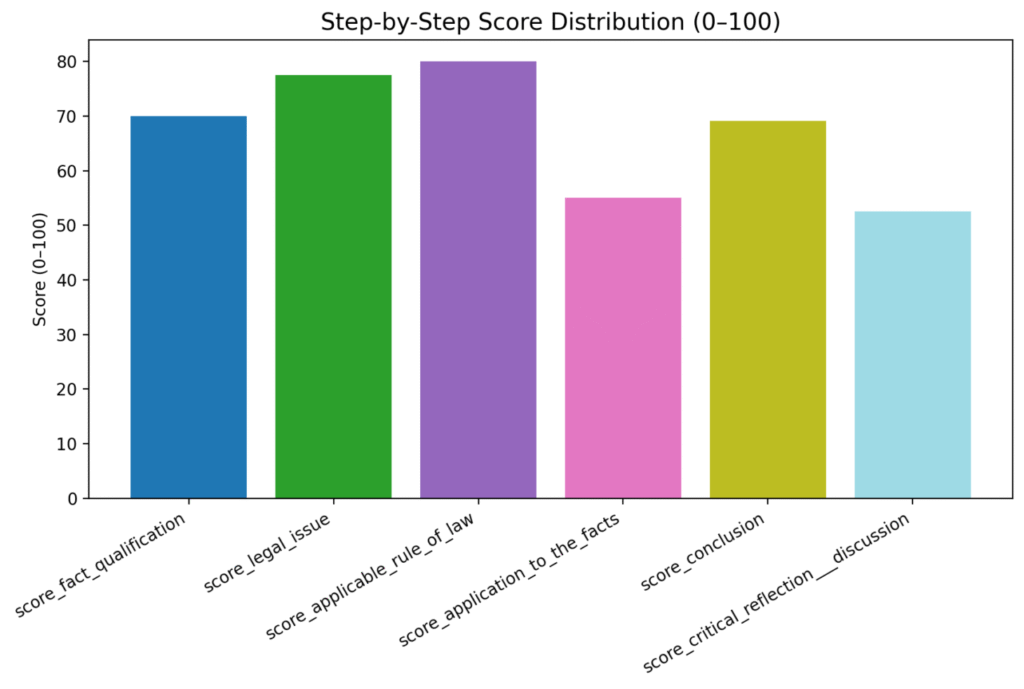
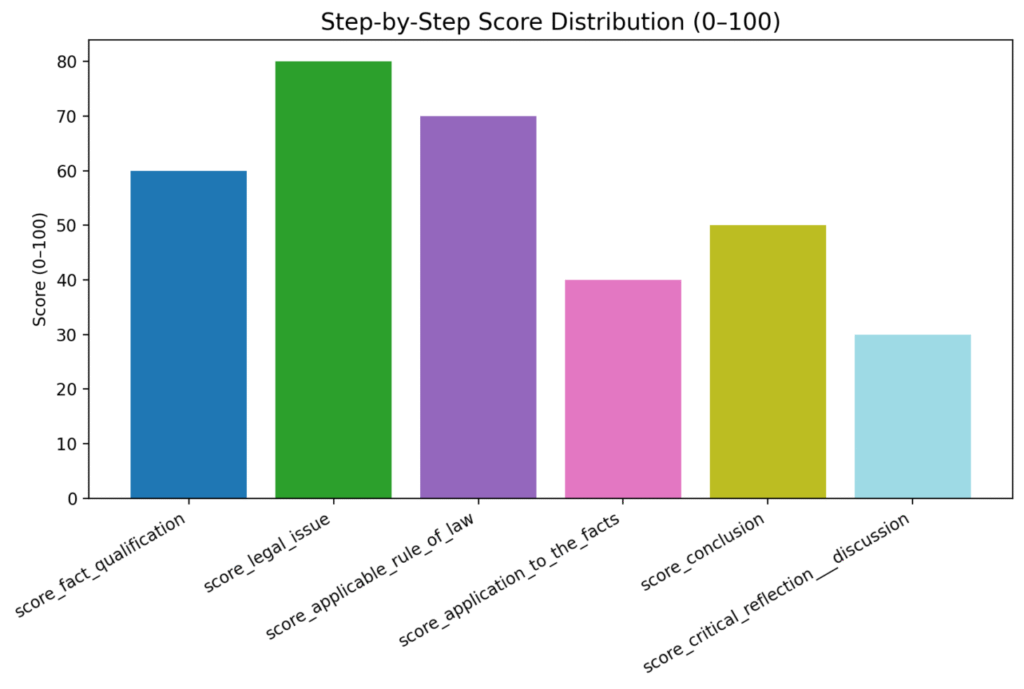
🔍 What We Evaluated (6 Legal Reasoning Dimensions)
For each model, the system scored:
- Fact Qualification
- Legal Issue Identification
- Applicable Rule of Law
- Application to the Facts
- Conclusion Quality
- Critical Reflection / Discussion
Each item scored /100, plus a final overall score.
📈 What the Results Reveal About Today’s Legal AI Models
1. GPT-5 leads the legal reasoning race
It:
- cites correct UK cases
- structures the “last straw test”
- applies multi-step reasoning
- weighs evidence and counterarguments
GPT-5 is the only model offering a law-school-grade application section.
2. Gemini shows impressive balance
Not as technical as GPT-5, but:
- solid doctrinal structure
- strong narrative clarity
- good understanding of UK employment law fundamentals
It is highly usable for compliance teams.
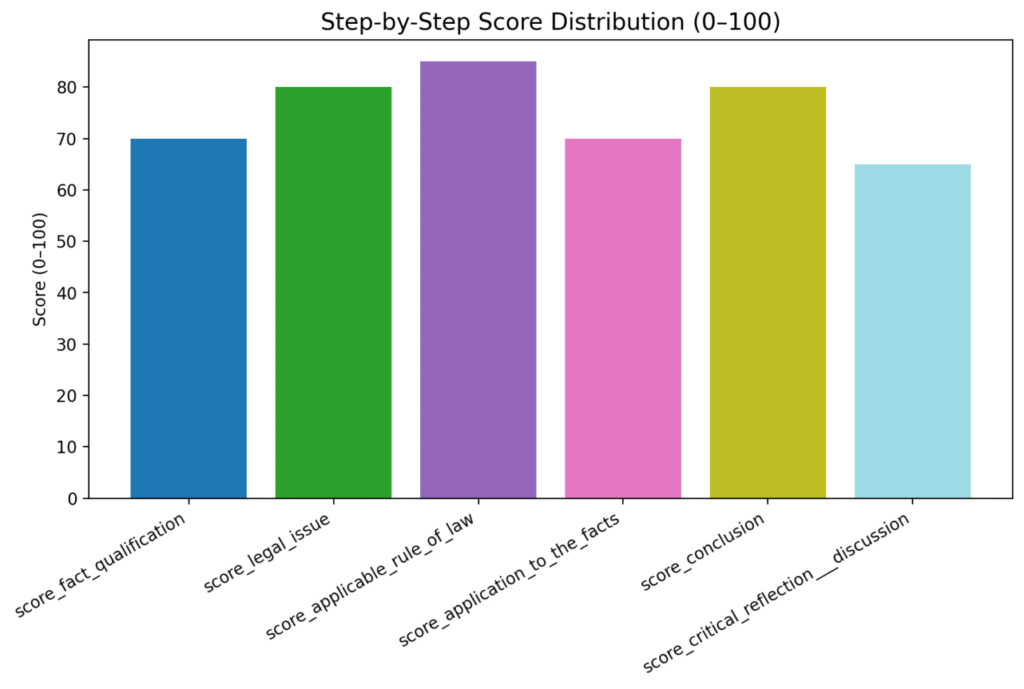
3. Grok demonstrates strong logic but lacks legal granularity
It handles:
- structure
- logic
- general legal concepts
…but struggles with:
- doctrinal depth
- statutory precision
- case-law connections
Very good for high-level reasoning, not litigation.
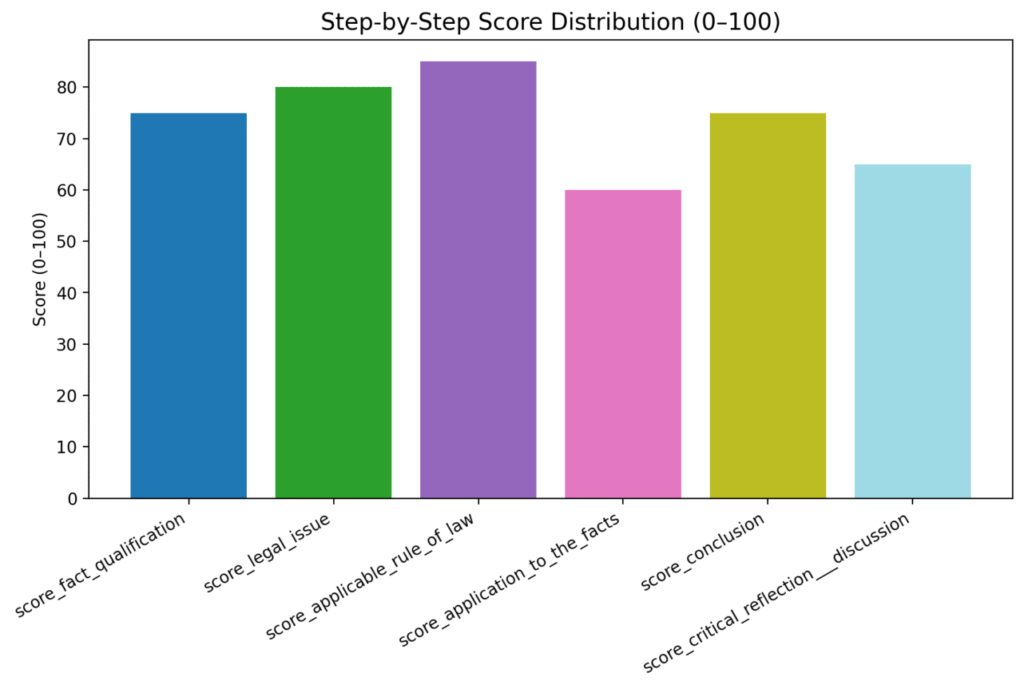
4. Mistral & Claude underperform on UK-specific law
They provide:
- correct general concepts
- acceptable structure
But they often fail to:
- cite case law
- apply the facts rigorously
- understand UK-specific legal doctrine
Their reasoning looks like “HR blog posts,” not legal analysis.
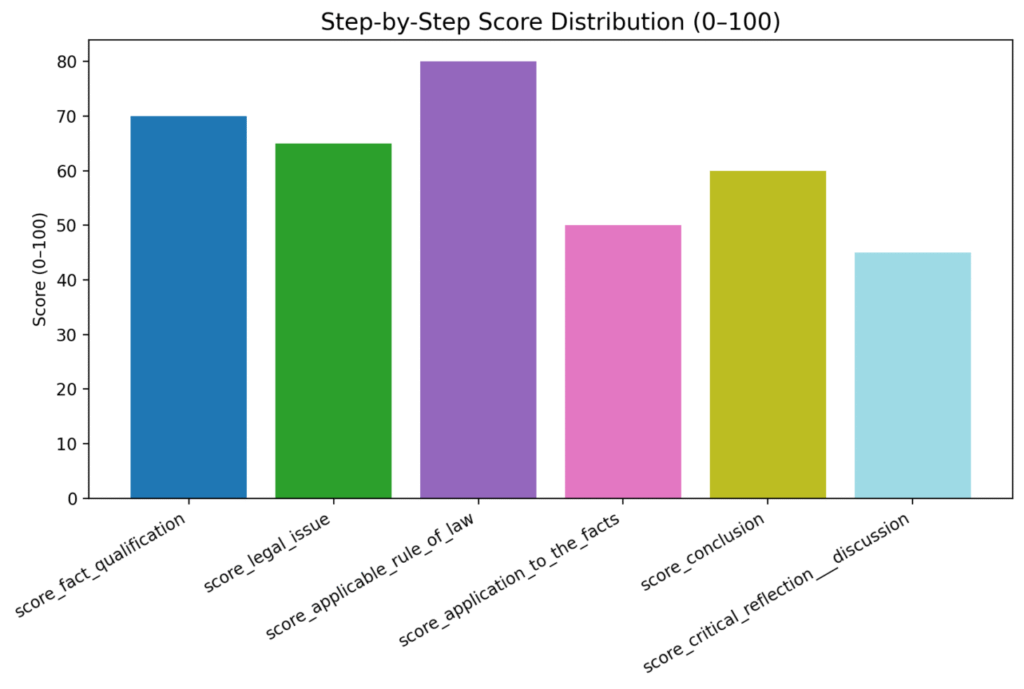
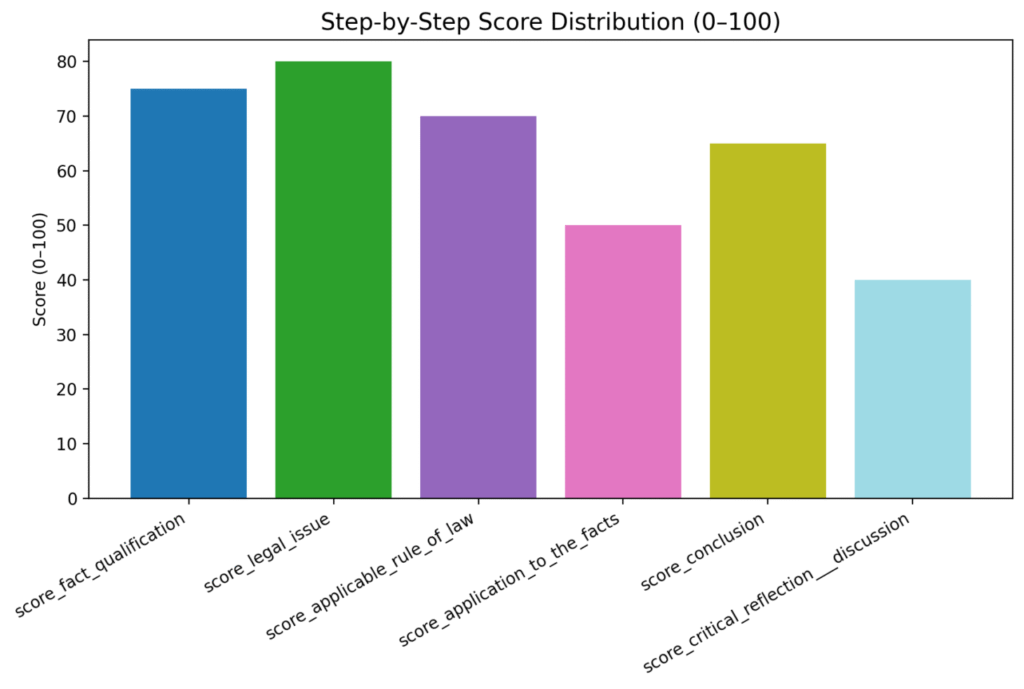
5. GPT-4o shows its limits for legal reasoning
Surprising result:
➡️ GPT-4o gets 54/100, the lowest score.
It fails to:
- structure facts correctly
- articulate legal issues precisely
- reference key doctrines
It performs like a generic assistant, not a legal model.
🎯 Conclusion: A Market-Ready Benchmark for Legal & Compliance Teams
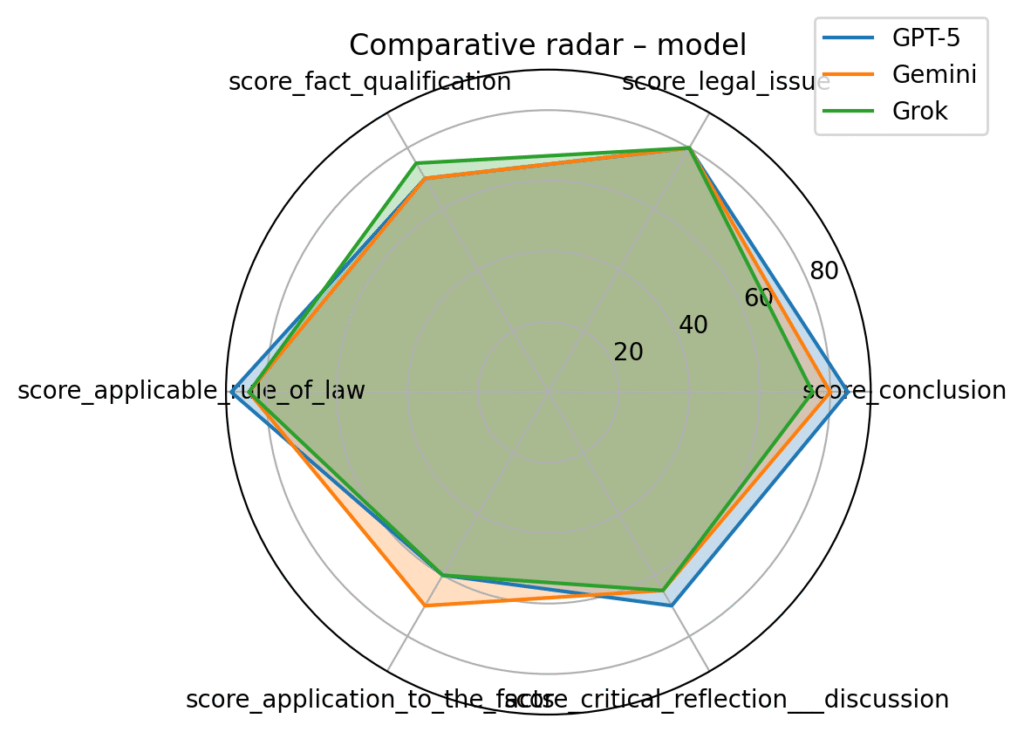
1️⃣ GPT-5 and Gemini clearly dominate
They provide the closest to a junior lawyer’s reasoning, integrating statute + case law + doctrine.
2️⃣ Grok is surprisingly strong
More concise than GPT-5/Gemini but more solid than GPT-4o.
It shows good legal alignment and structure.
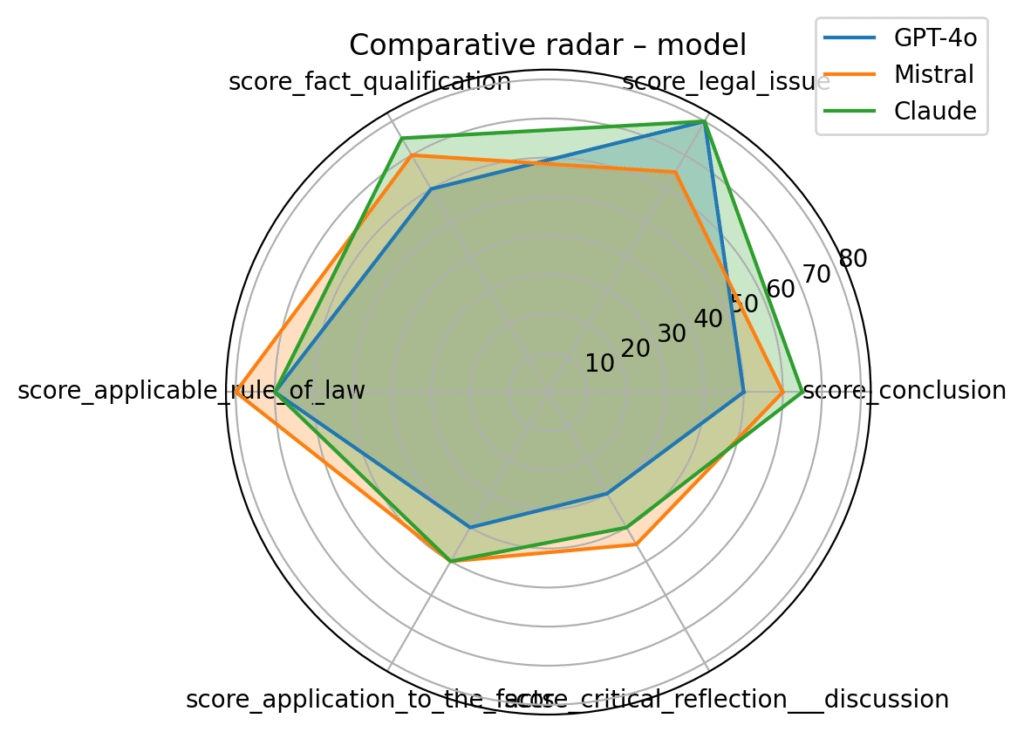
3️⃣ GPT-4o is far behind
It performs well in narrative tasks but lacks legal analytical depth.
4️⃣ Claude and Mistral are mid-pack
Useful but require strong guardrails and prompts for legal precision.